

生成AIの安全性を高める最新技術「DeliberativeAlignment」とは?ポリシー文書を読み込み、状況に応じた判断を下せる!!
生成AIの安全性を飛躍的に向上させる「DeliberativeAlignment」とは? ポリシー文書を学習する新技術が、ビジネス活用を加速させます。
💡 生成AIの安全性を高める新しいアライメント手法「DeliberativeAlignment」が登場しました。
💡 従来のアライメント手法では、モデルは人間のフィードバックから間接的に安全性を学習していましたが、DeliberativeAlignmentではポリシー文書を直接理解し、状況に応じた判断を下せるようにします。
💡 DeliberativeAlignmentは、OpenAIのo-seriesモデル(o1、o3など)に適用され、安全性と柔軟性を向上させることで、顧客サポートや情報検索、コンテンツ制作などの多様な業務にAIを活用できる範囲を広げます。
それでは、生成AIの安全性を高める最新技術である「DeliberativeAlignment」について詳しく見ていきましょう。
生成AIの安全性を高める「DeliberativeAlignment」
生成AIの安全性向上に貢献するDeliberativeAlignmentとは?
ポリシー理解で自律的判断
なるほど、従来のAIでは対応できなかった状況にも対応できるようになるんですね。
公開日:2024/12/21
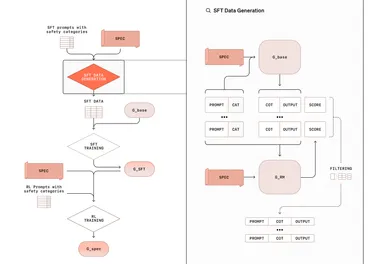
✅ Deliberative Alignmentは、AIモデルがポリシー文書を読み込み、その内容を理由づけと合わせて回答生成時に参照することで、従来のアライメント手法よりも柔軟で強固なアライメントを実現する新たな手法です。
✅ 従来のアライメント手法では、モデルは人間のフィードバックから間接的に安全性を学習していましたが、Deliberative Alignmentではポリシーを直接理解し、状況に応じた判断を下せるため、ジャイルブレイク攻撃への耐性や過剰な拒否と不十分な拒否の同時改善が可能になります。
✅ Deliberative Alignmentは、OpenAIのo-seriesモデル(o1、o3など)に適用され、安全性と柔軟性を向上させることで、顧客サポートや情報検索、コンテンツ制作などの多様な業務にAIを活用できる範囲を広げ、ユーザー満足度向上、業務効率化、コスト削減などビジネスメリットをもたらします。
さらに読む ⇒ainow出典/画像元: https://ainow.jp/chatgpt-o3/DeliberativeAlignmentは、生成AIの安全性を高める上で非常に重要な技術だと感じます。
DeliberativeAlignmentは、生成AIの安全性を高める新しいアライメント手法。
従来のRLHFやCAIでは学習された事例から逆算して安全性を判断していたため、新たな状況や攻撃パターンに脆弱性がありました。
DeliberativeAlignmentは、モデルに明示的な安全仕様(ポリシー文書)を読み込ませ、それを「理由づけ」と併せて回答生成時に参照させることで、ポリシーそのものを理解し、自ら判断を下せるようにします。
OpenAIのo-seriesモデル(o1、o3など)は、DeliberativeAlignmentを採用し、従来のモデルを大幅に超える安全性を実現。
ポリシー違反のリクエストには厳格に対応しながら、オーバーリフューザル(過剰な拒否)を減らし、ジャイルブレイク攻撃への耐性を高めています。
ビジネス面では、DeliberativeAlignmentにより、より安全で柔軟なLLMを活用することが可能になります。
これは、顧客サポートや情報検索、コンテンツ制作など、さまざまなタスクへのAI導入を促進し、ユーザー満足度向上、業務効率化、コスト削減といったメリットをもたらすでしょう。
DeliberativeAlignmentは、モデルが直接ポリシー文書を学習することで、従来の手法に比べてより高いレベルの安全性を確保し、生成AIのビジネス活用における新たな可能性を広げます。
これはすごいですね!従来のAIでは、倫理的な問題やセキュリティ上の問題が懸念されていましたが、DeliberativeAlignmentによって、より安全で信頼性の高いAIモデルが実現できるようになるかもしれません。
DeliberativeAlignmentは、生成AIの安全性を高め、ビジネス活用を促進する上で非常に重要な技術と言えるでしょう。
💡 生成AIの安全性向上に貢献する新しいアライメント手法「DeliberativeAlignment」が登場しました。
💡 DeliberativeAlignmentは、ポリシー文書を直接理解することで、より安全で柔軟なAIモデルを実現します。
💡 DeliberativeAlignmentは、顧客サポートや情報検索など、様々な業務におけるAI活用を促進し、ビジネスの効率化に貢献する可能性を秘めています。